En UX Research ou en étude de marché Marketing ou Politique, comme en sciences sociales, les méthodes de recherche quantitatives sont souvent basées sur :
- des suivis (diary study)
- des sondages
- des interview massives facilitées par IA
Le chercheur va poser des questions ou observer des comportements. Il doit définir son protocole
Causes et effets
En recherche quantitative, on cherche des causes et effets (va savoir pourquoi ?) ce qui donne deux types de variables :
- Variable indépendante - De cause (VI) :
C’est la variable que le chercheur manipule ou observe pour voir son effet. Elle est considérée comme la cause potentielle.
Exemple : le nombre d’heures d’étude. - Variable dépendante - D’effet (VD) :
C’est la variable mesurée, celle dont on observe les variations en fonction de la variable indépendante. Elle représente l’effet ou la conséquence.
Exemple : le score à un examen.
Exemple simple :
Si tu veux tester si le sommeil influence la concentration :
- VI : nombre d’heures de sommeil
- VD : performance à un test de concentration
Le postulat du chercheur est que VI ne peut pas être influencé par VD, mais l’inverse est possible… (ce postulat est rarement questionné, serait-ce un blind spot méthodologique? Imagine un monde où la causalité peut fonctionner du futur vers le présent et pas seulement du passé vers le présent…)
Corrélation ≠ causalité
on peut trouver une corrélation entre deux variables, même si l’une ne peut pas logiquement être une conséquence de l’autre. Cela peut indiquer :
- Une relation causale inversée (la cause supposée est en fait l’effet)
- Une variable tierce cachée (facteur confondant)
- Une corrélation fortuite (hasard ou biais)
Mais attention : corrélation ≠ causalité. C’est pourquoi les chercheurs insistent sur la rigueur dans le choix de la variable dépendante.
il y a toujours des facteurs non observés, des biais potentiels, des limites de mesure. C’est pourquoi les chercheurs parlent souvent de relations causales probables, pas de vérités absolues.
Même dans les sciences dures, comme la physique, la causalité est modélisée, pas observée directement.
🐣 L’œuf ou la poule ?
Dans certains cas, la cause et la conséquence sont mutuellement influentes. On parle alors de rétroaction ou de causalité circulaire. Exemples :
- Stress ↔ sommeil
- Éducation ↔ revenu
- Confiance ↔ performance
Dans ces cas, on utilise des modèles statistiques plus complexes comme :
- Les modèles à équations simultanées
- Les modèles de régression vectorielle autorégressive (VAR)
- Les modèles de médiation/modération
Les types de plan de recherche
Plan expérimental :
- Implique la manipulation d’une variable indépendante pour observer son effet sur des variables dépendantes.
- La population échantillon est répartie aléatoirement entre un groupe témoin et un groupe d’intervention.
- Exemple : Changer le goûter d’un élève (passer de pommes à des crackers) pour observer l’effet sur ses résultats aux tests.
Plan quasi-expérimental :
- Semblable au plan expérimental, mais sans répartition aléatoire.
- Utilise des groupes préexistants (par exemple, des normes géographiques ou culturelles) au lieu d’un échantillonnage aléatoire.
- Exemple : Étudier l’effet d’une méthode d’enseignement sur des élèves de différentes classes.
Plan corrélationnel :
- Étudie la relation entre deux variables ou plus sans les manipuler.
- Permet d’identifier des tendances ou des schémas, mais ne peut pas établir de lien de causalité.
- Exemple : Explorer la relation entre la consommation de crackers et les résultats aux tests.
Plan descriptif :
- Documente les variables d’un point de vue narratif sans tester d’hypothèse.
- Utilise des statistiques comme la moyenne, la médiane et l’écart-type pour mesurer des éléments quantitatifs.
- Exemple : Examiner les habitudes d’étude des étudiants vivant sous le seuil de pauvreté.
Poser une bonne question de recherche
- Ce n’est pas une simple curiosité, la réponse doit avoir une importance pour toi et ton audience
- C’est mieux si les résultats résonnent avec le vécu de ton audience, ainsi ils se l’approprieront
- Vérifie qu’il y a un socle de recherche sur lequel te fonder, sinon ta question ne pourra pas être reliée au corpus existant
- Définis bien les variables et leurs relation pour éviter toute ambiguité sur le cadre de ta recherche et ce que tu essaie de prouver
| Mauvais exemple | Bon exemple |
|---|---|
| What is the effect of poverty on education in the United States? | What is the correlation between a child’s family income level and likelihood of graduation from postsecondary education? |
Types de questions de recherche :
-
Questions relationnelles : Examinent la relation entre deux variables ou plus (par exemple : « Quelle est la relation entre la pauvreté durant l’enfance et les taux de diplomation chez les étudiants universitaires ? »).
-
Questions descriptives : Mettent en évidence quelque chose qui existe, en commençant généralement par « combien », « comment » ou « quoi » (par exemple : « Combien d’étudiants universitaires ayant vécu la pauvreté durant l’enfance abandonnent leurs études avant l’âge de 24 ans ? »).
-
Questions causales : Demandent si une variable cause ou influence une autre (par exemple : « Quelle est la différence dans les taux de diplomation en médecine préclinique entre les étudiants travaillant moins de 15 heures par semaine et ceux travaillant plus de 15 heures par semaine ? »).
Réplication de la recherche
Répliquer une étude dans différents contextes permet de garantir la validité et la fiabilité des résultats, en confirmant que ceux-ci ne sont pas dus au hasard ou à des circonstances particulières.
Pour une meilleure réplicabilité, veille à avoir une documentation détaillée
Biais de recherche
Biais de recherche
Biais de recherche modérée
Pour une recherche modérée, Effet Hawthorne
Biais des sondages
Les sondages sont basés sur la représentativité de l’échantillon, bien plus que sa taille. Si l’échantillon est mal constitué, il ne représente pas la population et le sondage est fallacieux. Voici trois biais classiques.
Le biais du volontaire consiste en une auto-sélection des répondants. Si vous postez un sondage en ligne pour demander aux gens s’ils aiment les sondages, vous aurez plus de chances d’avoir des réponses positives.
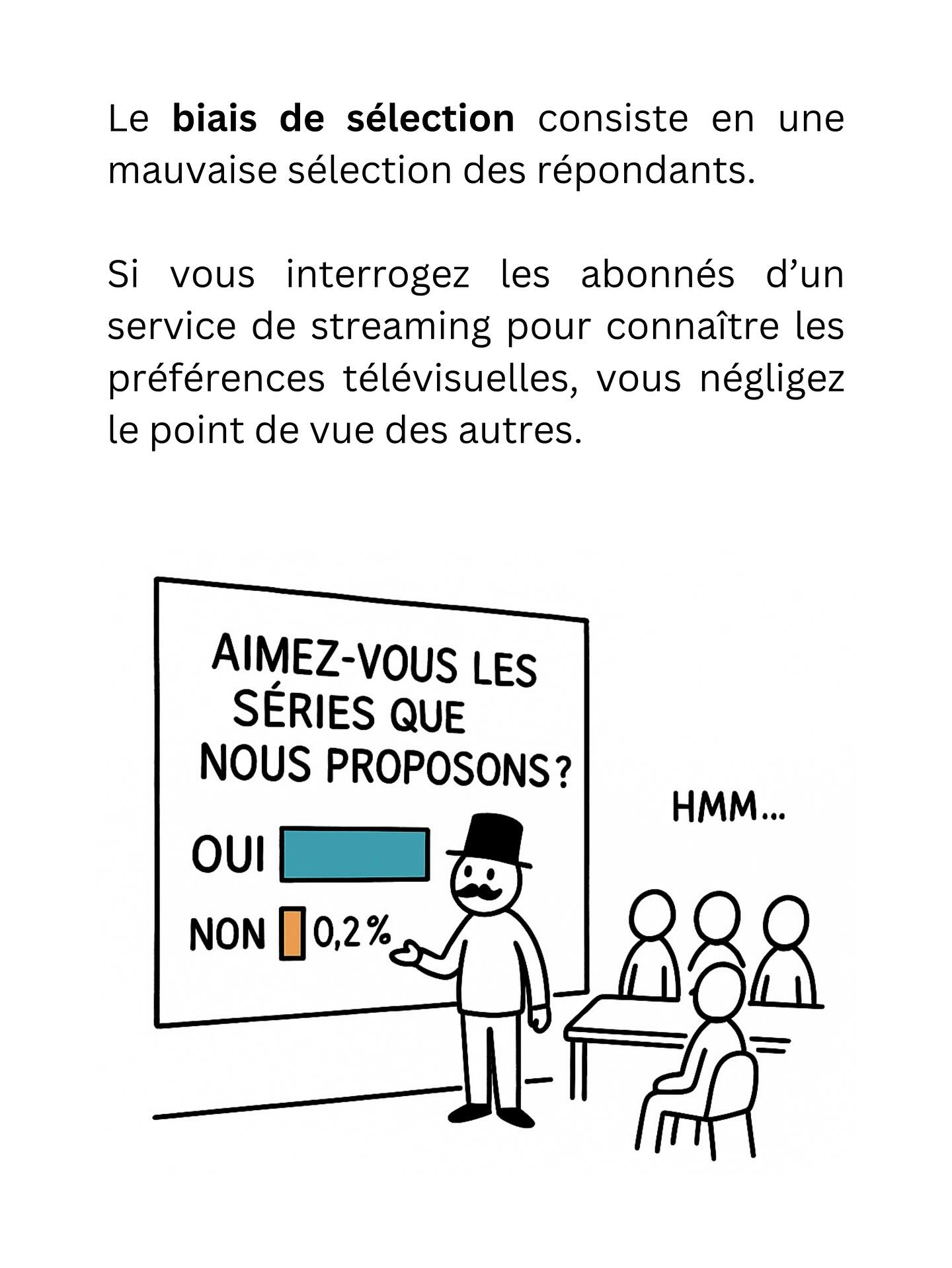
Le biais de sélection consiste en une mauvaise sélection des répondants. Si vous interrogez les abonnés d’un service de streaming pour connaître les préférences télévisuelles, vous négligez le point de vue des autres.
Le Biais de succès ou du survivant consiste à interroger uniquement ceux qui sont passés à travers une certaine sélection. Si vous interrogez les étudiants qui ont réussi leur année, vous ne connaîtrez pas l’opinion des étudiants qui ont raté.
Prudence avec les sondages. (source)
Provient de : Quantitative Research
Lien vers l'original